


La construction de Britannica Online
Par Robert McHenry
Ancien rédacteur en chef de l’Encyclopaedia Britannica
Introduction
Si, vers 1985, quelqu’un avait posé la question, volontairement ou non, « La Britannica a-t-elle déjà été numérisée ? », la réponse aurait été « Oui, et en fait nous en sommes déjà à notre troisième système informatique ». La publication d’une révision annuelle d’une encyclopédie de 32 000 pages est une entreprise majeure, et le développement de systèmes informatiques pour traiter cette énorme quantité de données promettait des économies tout aussi importantes.
Le texte de l’encyclopédie a été numérisé pour la première fois vers 1977 ; les données ont alimenté un appareil de photocomposition RCA PhotoComp qui a produit le film de page à partir duquel les plaques d’impression offset sont créées. En 1981, les données ont été transférées vers un système Atex plus puissant, un système principalement utilisé par les journaux parce qu’il offrait un ensemble d’outils d’édition très robustes. Mais lorsqu’une révision complète de l’encyclopédie a été entreprise – une révision dans laquelle chaque page du jeu devait être recomposée, au lieu des 1 000 ou 2 000 pages habituelles depuis quelques années – Atex s’est avéré inadéquat. Il a été remplacé en 1984 par le système de publication intégré, ou IPS, une solution purement logicielle développée par la branche éditoriale Watchtower des Témoins de Jéhovah.
La Watchtower ayant un programme de publication très lourd dans une soixantaine de langues, elle a pris l’initiative de développer un système doté de bons outils d’édition et d’un moteur de composition WYSIWYG, et qui gère nativement un très grand nombre de caractères alphabétiques et symboliques. La commercialisation, l’octroi de licences et l’assistance pour IPS ont été assurés pour les témoins par IBM, sur l’ordinateur central duquel il a été conçu pour fonctionner. Après avoir installé IPS, le groupe Editorial Computer Services de Britannica a entrepris un programme de personnalisation, ajoutant des fonctions telles que la césure et la justification, un vérificateur d’orthographe et divers outils de gestion éditoriale. Le segment d’édition d’IPS, appelé PSEdit, utilisait un système de balisage de texte qui, bien que propriétaire, était suffisamment proche du SGML pour être facilement convertible à ce système ou au HTML. (L’utilisation par PSEdit de la couleur et de la vidéo inversée en tant qu’attributs significatifs était moins facilement convertible). Un court article typique de Britannica, affiché sur un écran d’édition (un terminal IBM 3079) ressemblait à ceci :
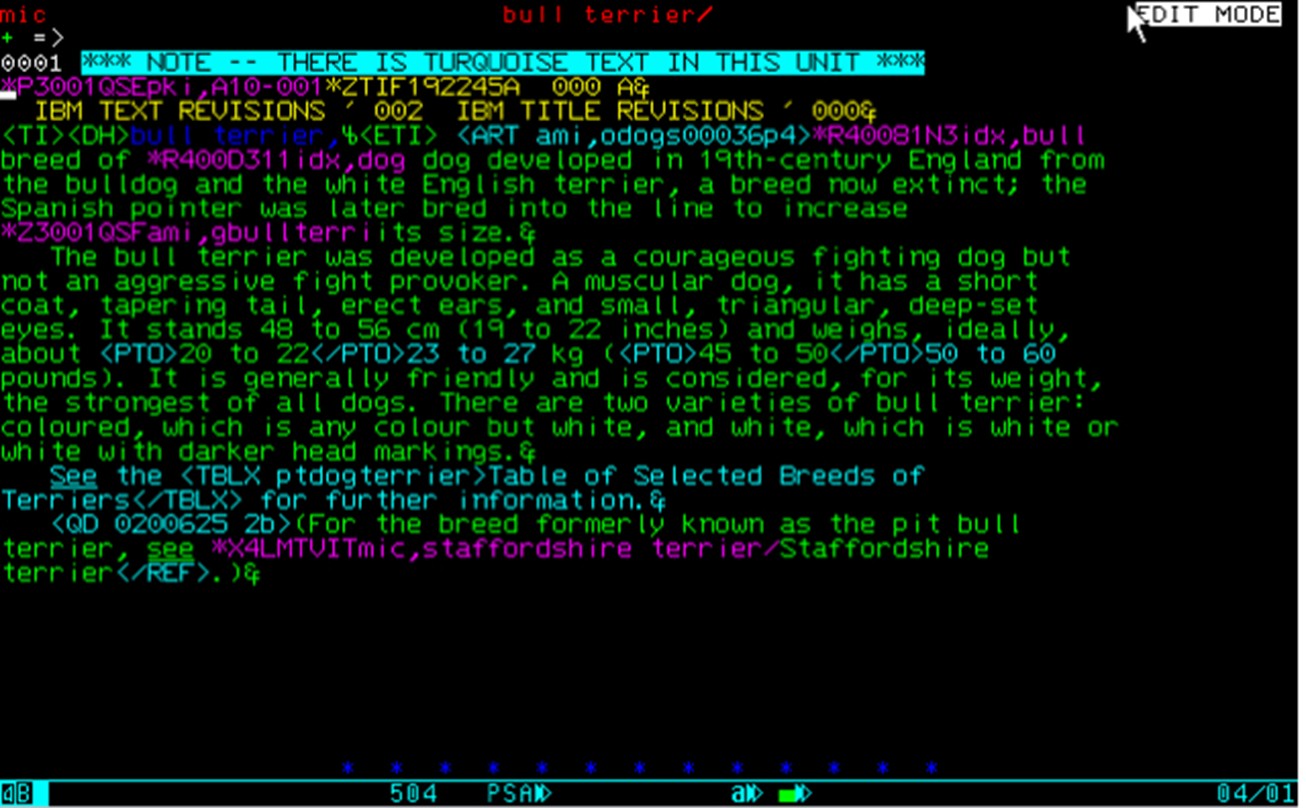
Un élément unique et essentiel de personnalisation ajouté par le groupe ECS était une méthode permettant d’insérer des balises métatexte, appelées crochets, dans les articles texte et de les relier de manière à ce qu’elles se comportent de façon analogue à ce que l’on a appelé plus tard les hyperliens. Ces balises étaient utilisées de diverses manières : pour relier les fichiers d’illustrations et leurs fichiers de légendes à des points du texte de l’article ; pour relier les références croisées à leurs référents ; pour relier des groupes d’articles liés entre eux par des thèmes au plan de Britannica appelé Propaedia ; et, surtout, pour relier les termes et leurs citations dans l’index aux points du texte d’où ils provenaient et vers lesquels ils renvoyaient. Dans le graphique ci-dessus, les chaînes roses sont les crochets. Les crochets de l’index et les crochets de la Propaedia seront plus tard exploités dans Britannica Online pour produire un système de navigation élaboré sur l’ensemble des 65 000 articles.
C’est au rédacteur en chef de Britannica qu’est revenue la tâche de « surfer » sur le Web, comme on l’appelait déjà, à la recherche de sites informatifs et faisant autorité sur une gamme encyclopédique de sujets. Il a d’abord demandé un écart budgétaire pour permettre l’embauche d’un rédacteur temporaire pour l’été, mais sa demande a été rejetée. De tels liens externes, a estimé le cadre supérieur qui a rejeté la demande, n’allaient pas constituer une caractéristique importante de BOL.
En l’occurrence, lors du verrouillage des données en vue de la publication en septembre, 398 liens vers d’autres sites Web ont été ajoutés à un nombre légèrement inférieur d’articles d’encyclopédie (quelques-uns comportant deux liens ou plus). La méthode de navigation s’est fortement appuyée sur la bibliothèque virtuelle créée sur le site Web principal du CERN, qui a fourni un ensemble d’URL organisé de manière topique à partir duquel commencer. Il est peut-être intéressant de noter que, même à cette époque, la ville de Hoboken, dans le New Jersey, disposait d’un site Web.
Première partie
Depuis le milieu des années 80, les personnes associées d’une manière ou d’une autre à l’Encyclopædia Britannica ont commencé à se poser la question suivante : « La Britannica est-elle déjà disponible sur ordinateur ? » ou, un peu plus tard, « Quand la Britannica sera-t-elle disponible sur CD ? ». Les questions, peu fréquentes au début, sont devenues de plus en plus insistantes à mesure que les années 90 s’ouvraient et que le format CD-ROM devenait plus familier. Nombreux sont ceux qui pensent aujourd’hui avoir vu l’encyclopédie Encarta de Microsoft sur CD-ROM en 1990 ou 1991. En fait, Encarta sur disque a fait ses débuts en 1993 et n’était ni la première encyclopédie sur CD-ROM – il s’agissait de Grolier’s, une encyclopédie en texte seul basée sur DOS, en 1985 – ni la première encyclopédie multimédia sur CD-ROM – il s’agissait de Compton’s MultiMedia Encyclopedia (une propriété de Britannica) en 1989.
À la fin des années 1990, la question s’est transformée en « Britannica est-elle déjà en ligne ? ». La réponse, qui surprend encore aujourd’hui certaines personnes, était « Oui, et en fait c’était la première ressource de référence de ce type disponible sur l’Internet ». Le fait qu’Encarta ait pu dominer le marché des encyclopédies sur CD-ROM dès son entrée sur le marché est imputable aux fonds inépuisables de Microsoft, à sa position sur le marché et à son mépris désinvolte pour la qualité du travail. Le fait que les premiers coups d’éclat de Britannica soient si peu connus s’explique par des facteurs qui dépassent le cadre de cet essai, mais dont le plus important est l’incapacité de la direction de l’entreprise à adopter l’édition électronique et à la poursuivre avec force.
Avec le recul, un nombre surprenant de personnes revendiquent aujourd’hui la paternité ou la maternité de Britannica Online. Une recherche rapide en ligne permet d’en trouver plusieurs. Lorsqu’un universitaire entreprendra enfin d’écrire une histoire complète de la société Britannica moderne, d’autres apparaîtront sans aucun doute. De peur que leurs versions de l’histoire ne deviennent trop fermement ancrées dans la sagesse conventionnelle, j’ai compilé l’esquisse suivante de la genèse et du développement initial de Britannica Online, en me concentrant entièrement sur les personnes qui l’ont réellement créé, qui ont eu les idées et fait le vrai travail, et qui, lorsque la société a finalement perdu non seulement son leadership initial mais aussi son sens de l’orientation, ne pouvaient que regarder en arrière avec nostalgie ce qui a été l’un des épisodes les plus gratifiants de leur carrière.
Contexte
Environnement de l’entreprise. Depuis sa création dans les années 1940 jusqu’en 1995 environ, la société Britannica moderne a vécu dans un état de tension, parfois créative, parfois non, entre deux parties à peu près égales, l’activité éditoriale et l’activité commerciale. Les ventes étaient intrinsèquement les plus fortes des deux, parce qu’elles étaient la source de financement et de croissance et parce que de nombreux cadres supérieurs de l’entreprise étaient issus de l’organisation des ventes. La rédaction a pu se maintenir principalement grâce à l’influence extraordinaire exercée par Mortimer Adler. On pourrait écrire un autre essai sur la puissante personnalité d’Adler ; il suffit ici de noter qu’il avait l’oreille des présidents successifs du conseil d’administration et le soutien de la plupart des membres du conseil ainsi que d’importantes personnes extérieures à l’entreprise.
L’organisation des ventes reposait sur la vente directe à domicile. C’était un article de foi qu’un produit d’achat discrétionnaire à prix élevé comme une encyclopédie ne pouvait être vendu d’aucune autre manière, ou du moins pas dans le volume nécessaire pour soutenir l’entreprise. La force de vente sur le terrain utilisait des prospects, certains générés par le marketing local, mais la plupart générés par la société par le biais de la publicité nationale et d’autres moyens (et alimentés par un budget qui dépassait le budget éditorial), et pour presque chaque vente, elle renvoyait à la société un contrat d’achat à terme et un petit acompte. Le vendeur, son directeur de district, le directeur régional de ce dernier et le vice-président des ventes le plus proche percevaient tous une commission sur la vente. Le coût des marchandises (en 1990, environ 300 dollars) et le coût de la vente ont été financés par les paiements futurs à recevoir. L’une des conséquences de ce système à fort effet de levier était une volonté incessante de recruter davantage de vendeurs, afin de produire davantage de créances. Une autre conséquence a été une sensibilité démesurée de la part des cadres supérieurs des ventes à ce qu’ils jugeaient être l’humeur et le moral de la force de vente sur le terrain.
La direction n’ignorait cependant pas la révolution des technologies de l’information qui commençait à toucher le marché des consommateurs dans les années 1980. Alors que la Britannica et son texte étaient interdits (à une exception près), l’entreprise disposait d’un autre produit à expérimenter, l’encyclopédie Compton’s. Celle-ci était destinée aux jeunes lecteurs et était utilisée presque exclusivement comme prime dans les ventes de la série senior. L’encyclopédie Compton’s était destinée aux jeunes lecteurs et a été utilisée presque exclusivement comme une prime dans les ventes de la série senior. Le coût éditorial de la maintenance de Compton’s était en fait une dépense promotionnelle. On pensait que la force de vente n’aurait aucune objection à utiliser le nom et le contenu de Compton’s dans des produits électroniques.
CMME. En 1987, Britannica a été contactée par Educational Systems Corporation, une société de San Diego qui construisait un système de ressources d’étude en réseau pour les écoles et qui souhaitait inclure une encyclopédie sur CD-ROM dans l’ensemble. Britannica a refusé de mettre à disposition le texte d’EB et a proposé à la place celui de Compton. Même avec cette quantité moindre de texte à traiter, ESC a réalisé qu’elle aurait besoin d’une sorte de moteur de recherche de texte. Pour ce faire, elle s’est adressée au Del Mar Group, une petite société fondée par Harold Kester, qui disposait justement d’un tel moteur.
Le moteur du Del Mar Group, appelé SmarTrieve, était sans doute le moteur le plus précis et le plus efficace disponible à l’époque en dehors d’un laboratoire de recherche. Dans le contrat signé en mars 1988, le groupe Del Mar a non seulement concédé une licence à l’ESC pour l’utilisation de SmarTrieve dans le produit scolaire, mais il s’est également engagé à prendre en charge l’analyse du texte de Compton et à concevoir la structure globale des données pour une encyclopédie multimédia sur CD-ROM, comprenant des graphiques et des segments audio et vidéo. La conception de la structure de données, rédigée par Kester et Art Larsen, était apparemment la première du genre et a constitué par la suite un élément essentiel du brevet Compton contesté.
L’encyclopédie Compton’s MultiMedia Encyclopedia (CMME) a fait l’objet d’une première démonstration publique en avril 1989 lors d’une conférence éducative à Anaheim, en Californie, par Greg Bestick de ESC, aujourd’hui appelé Josten’s Learning Corporation. Dans un résumé de fin d’année, le magazine Business Week a désigné CMME comme l’un des dix meilleurs nouveaux produits de l’année. Britannica, qui a conservé le droit de commercialiser CMME sur le marché des consommateurs, commence à le vendre l’année suivante. La version originale, adaptée à l’ordinateur Tandy de Radio Shack, a été suivie en 1991 d’une version Windows et, peu de temps après, d’une version Mac. Au cours de cette même période (je n’ai pas encore trouvé la date exacte), un accord a été conclu pour accorder une licence sur le texte numérisé de Compton à Trintex, un service d’information destiné aux consommateurs et fonctionnant sur un réseau propriétaire. (Trintex, après le retrait de l’un de ses trois partenaires initiaux, est devenu le service Prodigy).
Britannicas électriques
Les premiers disques. Alors que CMME en était encore à sa phase initiale de développement, Kester a jeté son dévolu sur le texte EB. Lors de l’exposition CD-ROM de Microsoft en février 1989, il avait montré à un cadre de Britannica Learning Corp. comment les données numérisées de Compton, exécutées sous SmarTrieve, pouvaient presque instantanément fournir une réponse à la question « Pourquoi les feuilles tombent-elles des arbres à l’automne ? En septembre, il a fait une démonstration de la technologie SmarTrieve au siège de Britannica à Chicago et, le mois suivant, il a obtenu un accord lui permettant d’accéder aux données du texte EB. Comme il s’en souvient, il a fallu à ses deux ordinateurs IBM 80286 quelque trois mois de traitement continu pour analyser l’ensemble du texte EB (dans un format propriétaire appelé BSTIF, pour Britannica Software Tagged Interchange Format) et produire l’index inversé. Bien que ce travail lui ait apporté une grande satisfaction, il ne présentait qu’un intérêt secondaire pour Britannica à l’époque. En mars 1990, Britannica a racheté le Del Mar Group, et avec lui les droits de SmarTrieve, et l’a intégré à la division Britannica Software (rebaptisée Compton’s New Media en 1992). La priorité a été donnée au développement du CMME grand public pour diverses plates-formes et à un ambitieux programme d’édition de CD-ROM grand public, allant du Livre Guinness des records aux Ours Berenstain.
La recherche d’une application pour les données EB, qui pourrait être réalisée comme s’il s’agissait d’un temps libre et qui n’alarmerait pas la direction des ventes, a débouché sur le Britannica Electronic Index, ou BEI. BEI fonctionnait sous DOS et était essentiellement l’index SmarTrieve des données EB sur un CD-ROM. Une requête tapée au clavier produisait une liste de références au texte classées par ordre de pertinence, sous la forme de citations volume-page-quadrants (Encadré 3). (Encadré 3) Pour l’utilisateur, BEI était censé fonctionner comme un super index, dépassant de loin l’index imprimé en deux volumes en termes d’exhaustivité et, contrairement à l’index imprimé, capable de traiter des requêtes impliquant plus qu’un seul terme. En tant que produit, il s’agissait d’un cadeau – un autre article de prestige utilisé dans l’espoir de promouvoir les ventes de la série imprimée.
Le premier véritable produit électronique Britannica est né en partie d’une vague de publicité générée au milieu de l’année 1991 par les critiques de certains manuels d’histoire pour lycéens, qui s’étaient révélés truffés d’erreurs factuelles. Il s’est avéré que la plupart des éditeurs de manuels scolaires s’en remettaient à des fournisseurs de services externes pour la vérification des faits telle qu’elle était effectuée lors de l’élaboration des manuels, et que souvent, aucune vérification n’était effectuée du tout. La vérification des faits est lente, fastidieuse et difficile. Un produit électronique doté de capacités de recherche et d’extraction sophistiquées, fonctionnant sur une base textuelle supérieure, pourrait rendre le processus plus efficace et plus rentable. C’est de cette idée qu’est née la notion de Britannica Instant Research System, ou BIRS (d’abord connu en interne sous le nom de « Fact Finder »). Destiné à l’utilisateur professionnel, le BIRS fonctionnait sous Windows 3.0 et se composait de deux CD-ROM, l’un contenant les index SmarTrieve et l’autre le texte de la Britannica. Le contenu des deux disques devait être transféré sur le disque dur du PC de l’utilisateur, qui devait donc avoir une capacité d’un gigaoctet, ce qui était très important et très cher pour l’époque. BIRS a été lancé en juin 1992 avec ce qui était pour Britannica une fanfare substantielle, mais il n’a été acheté que par quelques clients audacieux, y compris la petite société de services éditoriaux basée à Evanston (Illinois) qui avait servi de site bêta.
« Réseau Britannica ». Tout en réussissant à faire sortir BEI et BIRS, et donc à faire entrer le nez du chameau dans la tente, Kester avait fait pression pour obtenir un budget indépendant afin de soutenir la recherche sur la manière dont les données de base de Britannica – non seulement les textes mais aussi les textes indexés et classés – pourraient être exploités au mieux par voie électronique. Il a constitué une équipe dont les principaux membres étaient John Dimm, qui travaillait déjà pour Britannica Software par l’intermédiaire de l’ESC, Bob Clarke, consultant et voyant indépendant avec lequel Kester avait travaillé dans les premiers temps du Del Mar Group, John McInerney, dont l’expérience portait sur l’administration et la sécurité des réseaux, Rik Belew, professeur d’informatique à l’UC San Diego, qui a servi de consultant à temps partiel, et deux doctorants de son département, Brian Bartell et Amy Steier. À la fin de l’année 1992, ces derniers ont formé un groupe distinct et quelque peu isolé au sein de Compton’s New Media, qui a été formellement organisé sous le nom de Advanced Technology Group en avril 1993. En août 1993, l’ATG a quitté les bureaux de Compton à Carlsbad, en Californie, et a ouvert ses propres bureaux à La Jolla, près du campus de l’UCSD. Il convient également de mentionner ici un membre honoraire de l’ATG, Vince Star, qui supervisait le système de publication de la Britannica à Chicago et avait donc été chargé très tôt de préparer les données textuelles en vue de leur transfert au groupe de la côte ouest. L’introduction du courrier électronique dans le bureau de Chicago au début de 1993, d’abord et pendant un certain temps sur une base très limitée (limitée non seulement par les ressources et une courbe d’apprentissage, mais aussi par le fait qu’il s’agissait de courrier « elm », une application UNIX pour laquelle il fallait apprendre quelques rudiments d’un éditeur maladroit appelé « vi »), a eu pour effet de cimenter les relations entre l’ATG et quelques personnes engagées au siège.
L’objectif le plus précoce et le plus important de l’équipe ATG a été fixé par Clarke, qui a défendu avec force l’affirmation de Scott McNealy (de Sun Microsystems) selon laquelle « le réseau est la plate-forme ». Cette affirmation peut en fait être interprétée de deux façons, et Clarke a défendu les deux : D’une part, « le » réseau – l’Internet – était la norme émergente ; d’autre part, en tant que stratégie de développement, résoudre d’abord le problème le plus difficile – construire ce qu’il a appelé System Britannica, essentiellement une version en réseau de Britannica – constituerait une base solide à partir de laquelle on pourrait dériver des CD-ROM et d’autres versions.
Ainsi, ce qui a finalement été publié sous le nom de Britannica CD 1.0 (connu simplement sous le nom de BCD) en 1994 était en fait le produit réseau porté sur un disque pour être utilisé dans un PC qui était à la fois serveur et client.
Les problèmes étaient nombreux. Le texte de la Britannica comprenait un grand nombre de « caractères spéciaux », notamment des formes de lettres et des signes diacritiques utilisés dans des mots non anglais (souvent des noms propres), des symboles mathématiques et des notations scientifiques. La traduction du texte brut de la Britannica en ASCII ou dans les jeux de caractères plus larges mais encore limités utilisés dans Windows et d’autres plates-formes était difficile et sujette aux erreurs, et les résultats ont été jugés insatisfaisants par les rédacteurs de la Britannica. Ces translittérations ont également compromis la précision de l’indexation effectuée par le logiciel de recherche et d’extraction. Une grande partie des articles mathématiques et scientifiques (tels que des formules complexes ou des diagrammes chimiques) de la série avaient été créés comme « comp spéciaux » pour le processus d’impression – essentiellement des œuvres d’art qui n’avaient pas d’équivalent dans la base de données du texte numérisé et qui laissaient donc des « trous » lorsque le texte seul était utilisé. Beaucoup d’autres illustrations plus conventionnelles ont été considérées comme essentielles pour compléter le texte.
D’un point de vue technique, les problèmes étaient tout aussi complexes. Le texte brut était énorme – un peu plus de 300 Mo – et se composait de dizaines de milliers de fichiers distincts, un nombre qui a augmenté une fois que les articles de Macropaedia, dont certains comptaient plus de 250 000 mots, ont été divisés en morceaux gérables. Ensuite, il y avait la question de savoir pour quels réseaux concevoir, pour quelles vitesses de téléchargement et pour quels types d’affichage. Windows n’avait pas encore pénétré le marché des réseaux de manière significative, et les machines les plus couramment utilisées pour l’affichage des données étaient les « terminaux muets » VT100.
Au-delà des questions de mise en œuvre se posaient des questions plus vastes, auxquelles Clarke, en particulier, réfléchissait beaucoup : Quels produits réellement innovants et quelles méthodes entièrement nouvelles de représentation et d’utilisation de l’information pourraient résulter de l’apprentissage de l’exploitation de l’indexation de Britannica et des codes de classification par sujet utilisés pour étiqueter le texte ? Dans un environnement en réseau, quelles relations pourraient s’établir ou se développer entre le contenu de la Britannica et d’autres ressources d’information sur le réseau ?
Annus Mirabilis : 1993. Les efforts de l’ATG ont été stimulés de manière inattendue en janvier 1993, lorsque le département éditorial de Britannica a été contacté par des représentants de l’Université de Chicago, qui ont proposé de participer au développement d’une version de Britannica basée sur un réseau local, qui fonctionnerait sur le réseau du campus. L’université avait déjà acquis une expérience considérable dans le traitement de grandes bases de données textuelles, notamment les archives de l’ARTFL qui contiennent des documents sur la littérature française.
Les discussions se sont poursuivies pendant quelques mois et un certain nombre de prototypes ont été réalisés, mais la proposition n’a finalement pas abouti. Les résultats utiles de cet épisode sont au nombre de trois : une démonstration au cours de laquelle un texte de Britannica sur un serveur universitaire a été accessible par connexion commutée depuis la bibliothèque EB et affiché sur un PC dans un glorieux ASCII vert ; la crédibilité de la proposition selon laquelle il pourrait y avoir un marché pour un produit Britannica en réseau parmi les collèges, les bibliothèques et d’autres institutions ; et, lors de l’une des premières réunions, une mention du mot « Internet », entendu à ce moment-là pour la première fois du côté de Britannica.
Dès le départ, Chicago et La Jolla ont adopté des approches très différentes pour concevoir Network Britannica. À Chicago, il semblait naturel de supposer que le produit utiliserait un logiciel entièrement propriétaire. À La Jolla, les idées d’échange facile d’informations, de normes ouvertes et d’applications prêtes à l’emploi étaient très séduisantes. John Dimm, qui avait une expérience de première main dans le développement des différentes variantes du CMME de Compton et connaissait donc intimement la difficulté de l’approche spécifique à la plate-forme et la fragilité des résultats, s’est montré particulièrement ardent dans la défense de l’adoption (et de l’adaptation si nécessaire) de solutions disponibles et éprouvées. Il convient également de rappeler que même si le développement était axé sur les réseaux locaux, il fallait également prévoir une connexion par ligne commutée, ce qui, à l’époque, signifiait, au mieux, des taux de transfert de 9600 bauds.
Le premier pas concret dans la direction de solutions générales a été la décision d’abandonner SmarTrieve en faveur du moteur de recherche WAIS. WAIS (Wide-Area Information Server) avait été présenté deux ans plus tôt comme le premier moteur de recherche en texte intégral capable de fonctionner sur des bases de données multiples et distribuées. Un contact a été établi avec le bureau de WAIS à Mountain View, en Californie, et un accord formel a été conclu en peu de temps pour le partage des codes. Un programmeur de WAIS (Harry Morris) qui travaillait déjà sur la version 2 de WAIS a été le principal agent de liaison avec ATG, travaillant principalement avec Brian Bartell et Amy Steier. Le travail de Steier consistait à développer un logiciel capable de reconnaître des phrases dans un texte anglais et de les traiter comme des unités fixes pour l’indexation et la recherche. Bartell a cherché à améliorer l’estimation de la pertinence par le moteur de recherche en incorporant dans sa logique un certain nombre d' »experts » sensibles à certaines conditions, telles que l’occurrence d’un terme de recherche dans le titre d’un document, ou des occurrences multiples dans un document, ou des occurrences au début plutôt qu’à la fin d’un document. (Une conséquence mineure de cette association commerciale a été l’invitation faite au fondateur de la WAIS, Brewster Kahle, à prendre la parole lors de la conférence de rédaction de la Britannica en octobre 1993, où Vince Star et ses collègues sont apparus de manière mémorable avec des bonnets à hélice).
Le 14 avril 1993, le domaine « eb.com » a été enregistré auprès d’InterNIC, en grande partie à l’initiative de Clarke. Chicago était loin d’accepter l’Internet comme plate-forme pour Network Britannica, mais ATG allait de l’avant, protégé principalement par les 1 723 miles aériens qui le séparaient du siège social.
Jusqu’à l’été 1993, Dimm proposait d’adopter Adobe Acrobat comme visualiseur de documents pour Network Britannica. Le choix d’Acrobat était conforme à son opinion selon laquelle un logiciel établi et largement utilisé était préférable à une solution propriétaire. Acrobat, qui permet de visualiser les pages des documents, résoudrait le problème de l’affichage des formules et autres, mais pas celui de leur saisie. Il se trouve que Britannica envisageait à ce moment-là de faire appel à Adobe, entre autres, comme fournisseur d’un nouveau système pour remplacer IPS. Finalement, aucun des deux ne s’est concrétisé. Dimm a fait une présentation lors d’un cours d’informatique à l’UCSD et a assisté à une démonstration du World Wide Web, en utilisant le navigateur original de Tim Berners-Lee. Peu après, en juin 1993, il a vu une version pré-alpha de Mosaic lors de la convention des libraires américains à Miami. Il a immédiatement opté pour le Web en tant que plate-forme et pour Mosaic en tant que visionneuse pour Network Britannica. Au moment où Mosaic a été officiellement lancé, dans la version 0.5a en septembre, les défis de la conversion des données et de la mise en conformité de WAIS avec le Web et Mosaic étaient déjà en cours de résolution.
Un large échantillon de données EB a été analysé (à partir de BSTIF) en HTML en novembre et a pu être parcouru au moyen de Mosaic. Début décembre, l’ensemble de la base de données d’articles était opérationnel. Bartell et McInerney avaient écrit un programme cgi (common gateway interface ; un élément de codage standard plus tard mais un peu de science des fusées à l’époque) pour relier Mosaic, WAIS et la collection de documents. (Les caractères spéciaux posaient encore problème ; un échange de courriels concernait le caractère « æ », très important pour Britannica). McInerney avait construit les serveurs et le pare-feu nécessaires et avait créé un système d’authentification des utilisateurs basé sur leurs adresses IP. À une époque où cela était encore possible, McInerney a communiqué directement avec Marc Andreessen au centre NCSA de Champaign, Illinois, où Mosaic était en cours de développement, pour faire fonctionner correctement la passerelle WAIS-HTML.
Le résultat était une application qui invitait l’utilisateur à taper un ou plusieurs termes de recherche, qui étaient ensuite traités par WAIS afin de produire une liste de références de documents classées par ordre de pertinence. Ces références étaient ensuite présentées dans une page Web, créée à la volée, avec des liens directs vers les documents, qui étaient des articles ou des parties d’articles de Britannica. Dans les développements ultérieurs, cette page « hit-list » présentait un bref extrait de chaque document (pour permettre à l’utilisateur de faire une sélection plus éclairée), tandis que l’article retourné affichait le(s) terme(s) recherché(s) en caractères gras.
Au cours de la deuxième quinzaine de décembre, le pare-feu a été prudemment ouvert à quelques personnes extérieures au bureau de l’ATG, qui ont été invitées à y jeter un coup d’œil.
Rik Belew a pu consulter les articles de Britannica depuis son bureau sur le campus, tout comme un contact clé à la bibliothèque de l’UCSD, et Vince Star s’est connecté depuis Chicago. Les premières démonstrations semi-formelles ont eu lieu dans ce que l’on pourrait appeler la « salle des fêtes ».
Mensis Mirabilis : Janvier 1994. C’est au cours de ce mois qu’a eu lieu la première démonstration à l’équipe éditoriale de Chicago de EB Online, qui a reçu la bénédiction très discrète de la direction sous le nom de « Britannica Online ». Une démonstration à la classe d’informatique de Rik Belew le 14 janvier et une autre quatre jours plus tard aux membres du personnel de la bibliothèque de l’UCSD ont mis fin à la tranquillité. Aucune version de Britannica Online n’a jamais été déclarée version alpha officielle, mais s’il y en avait eu une, elle aurait été la version utilisée lors de ces deux démonstrations. La nouvelle s’est répandue très rapidement et, début février, la bibliothèque de l’UCSD s’est déclarée inondée de demandes d’accès à BOL. Pour la démonstration de Belew, John Dimm a ajouté un lien à la fin de l’article « Musées et bibliothèques du Vatican » vers l’exposition expérimentale « Vatican » de la Bibliothèque du Congrès (hébergée sur le « sunsite » très actif de l’Université de Caroline du Nord). Il s’agit du premier de ce que l’on a appelé dans BOL les « liens externes » et plus tard les « liens Internet connexes » (Related Internet Links ou RIL). En outre, à temps pour la démonstration de Belew, Dimm a mis en place un système de liens internes entre les listes classées d’articles connexes (dans le plan de Propaedia) et les articles eux-mêmes, permettant ainsi une navigation thématique. Le 20 janvier, Dimm a envoyé un courrier électronique au groupe de gestion des produits à Chicago, contenant le code HTML d’une page d’accueil publique de niveau alpha pour Britannica Online. Tout en bas de la page, il a copié les informations standard de l’éditeur figurant sur les pages de titre imprimées de chaque volume de Britannica, ajoutant sournoisement « La Jolla » après « Chicago » dans la liste des principaux centres d’exploitation de la société.
Le 8 février, à la suite d’une annonce faite par un haut responsable de Britannica lors de la convention des libraires américains à San Francisco, un article du journaliste technologique John Markoff est paru en page 1 de la section affaires du New York Times, intitulé « Les 44 millions de mots de Britannica vont être mis en ligne ». McInerney a immédiatement commencé à enregistrer des centaines de frappes sur le pare-feu protégeant les données. Des bêta-testeurs ont été recrutés dans diverses universités (Nancy Johns, de la bibliothèque de l’UIC, à Chicago, s’est montrée particulièrement enthousiaste ; des professeurs ou des membres du personnel de Stanford, Dartmouth et ? ? ont également participé au projet), et des testeurs volontaires ont commencé à se manifester à leur tour. L’un d’entre eux, connu simplement sous le nom de « Larry » et manifestement basé au département d’informatique de l’université de l’Idaho, a découvert BOL et a rapidement ajouté un lien vers celui-ci à partir de sa propre page d’accueil, qui présentait par ailleurs des graphiques inspirés de Metallica et d’autres groupes préférés. Son lien se résumait à « une bonne encyclopédie ». En revanche, « Joel », de l’université de l’Illinois, a rapidement adapté le plan de la Propaedia dans BOL pour un projet personnel et a dû se faire expliquer certains aspects de la loi sur le droit d’auteur par le service juridique de Britannica.
De février à la sortie officielle de Britannica Online 1.0 en septembre 1994, le travail de l’ATG et des personnes impliquées à Chicago a consisté principalement à affiner le concept. Le groupe d’indexation du département éditorial a été recruté pour effectuer des tests exhaustifs sur le moteur de recherche WAIS, dont les résultats ont ensuite été utilisés par Bartell et Steier pour affiner les « experts » propriétaires qui évaluent la pertinence des réponses aux requêtes. Vince Star a écrit l’analyseur syntaxique qui a produit des documents HTML directement à partir des données PSEDIT, éliminant ainsi l’étape intermédiaire gênante et « à perte » impliquant BSTIF. Les problèmes liés aux caractères spéciaux ont été en grande partie résolus (bien que les expressions mathématiques restent difficiles à gérer). Environ un dixième des illustrations de la version imprimée, soit quelque 2 200 au total, qui avaient été jugées essentielles par les éditeurs pour une utilisation et une compréhension complètes du texte, ont été saisies numériquement et reliées à leur emplacement dans les articles. Les crochets d’indexation des données PSEDIT, qui relient les points du texte de l’article aux entrées et aux citations de l’index imprimé, ont été convertis ultérieurement en balises href dans les données HTML, créant ainsi un réseau de quelque 1,2 million de liens internes à travers le texte de BOL. Un certain nombre de liens vers d’autres sites Web ont été ajoutés aux articles, ce qui montre comment BOL peut servir non seulement de source d’informations et d’instructions fiables en soi, mais aussi de guide édité vers le meilleur de ce que le Web peut offrir.
En septembre, le pare-feu a été ouvert aux établissements d’enseignement supérieur qui avaient déjà souscrit à BOL. Tout compte fait, la vente n’a pas été difficile. Alors que la bibliothèque universitaire typique achetait un seul jeu de Britannica, le rangeait dans un endroit isolé sur les étagères ouvertes et le remplaçait tous les cinq ans par une impression mise à jour, BOL était disponible instantanément pour chaque étudiant et membre de la faculté à partir de son bureau et était aussi à jour que les éditeurs et leurs collègues de l’ATG pouvaient le faire. Les informations qu’il contenait étaient mieux indexées, plus facilement navigables et donc plus accessibles que celles de la version imprimée, et il n’était jamais nécessaire d’attendre que le volume dont on avait besoin soit remis sur l’étagère.
La possibilité de démontrer la puissance de la mise à jour (presque) en temps réel a dû attendre le développement de nouvelles capacités techniques, notamment la capacité d’éditer, d’analyser, de WAIS-indexer et d’insérer un seul article dans la base de données. Le 6 septembre 1995, Cal Ripken Jr. des Orioles de Baltimore a battu le record de Lou Gehrig, vieux de 56 ans, pour le nombre de matchs consécutifs joués ; deux jours plus tard – les outils techniques étant encore assez rudimentaires – l’article sur Gehrig, qui indiquait que le record n’avait pas été battu depuis 1939, a été révisé pour reconnaître l’exploit de Ripken. Un petit pas pour un rédacteur, un pas de géant pour l’édition électronique.
Partie II
Dès sa première sortie en septembre 1994, Britannica Online a connu un grand succès auprès de son premier public cible : les collèges, les universités et les bibliothèques. Grâce au bouche à oreille, à l’aide de ses partenaires bêta-testeurs et aux efforts d’une minuscule force de vente, BOL s’est assuré une part de marché remarquable au cours des deux ou trois années suivantes. Quelques centaines d’institutions aux États-Unis se sont inscrites, de même qu’un certain nombre d’institutions à l’étranger qui ont pris l’initiative d’établir des contacts. Un an plus tard, à l’automne 1995, BOL a également été mis à la disposition des abonnés individuels, mais la pénétration de BOL sur le marché des consommateurs n’a jamais été à la hauteur des espérances de la société. L’une des principales raisons, sans aucun doute, était qu’au niveau institutionnel, aucune autre encyclopédie ne pouvait espérer égaler la réputation ou les performances de Britannica ; tandis que pour de nombreux consommateurs, à la recherche d’une aide aux devoirs pour les jeunes étudiants, il existait des concurrents crédibles, en particulier ceux qui étaient fournis gratuitement avec le plus récent des biens d’aspiration, le PC domestique.
Au moment de sa sortie initiale, BOL n’était pas considéré par la direction comme l’avenir de l’entreprise. Du point de vue du siège, la sortie de BIRS avait montré la voie à suivre pour produire une version CD-ROM grand public de Britannica que la force de vente pouvait accepter, à savoir une version dont le prix était le même que celui de la version imprimée. Bien que cela semble rétrospectivement presque incroyable, des acheteurs ont été trouvés pour BCD 1.0 à 1500 $. On peut se demander ce que ces quelques personnes pensent aujourd’hui de leur achat, ou même ce qu’elles en pensent six mois plus tard. Un programme standard de stratification des prix a suivi, avec des baisses de prix successives jusqu’à quelques centaines de dollars, en dessous desquels on craignait que la force de vente ne commence à se rebeller. Les disques n’étaient disponibles que par l’intermédiaire de la force de vente, mais à mesure que le prix du CD baissait, les commissions diminuaient également, et si personne ne savait exactement où se situait le plancher, il ne faisait aucun doute qu’il existait. Les suggestions de distribution au détail du CD étaient accueillies par des regards noirs ou pire.
L’orientation de la direction générale étant définie par l’orthodoxie de la vente directe, l’enthousiasme suscité par BOL était largement confiné au personnel de l’ATG, au groupe technique de Chicago, à de nombreux rédacteurs et à quelques autres. Le marché institutionnel de l’Encyclopædia Britannica avait toujours été très restreint, un peu plus qu’une réflexion après coup dans la planification des ventes et du marketing. BOL semblait produire plus d’argent que la version imprimée sur ce marché, mais pas assez pour faire du prochain président de la société un homme d’affaires.
En raison de cette attitude plutôt dédaigneuse à l’égard du projet – qui, de toute façon, n’était tolérée que dans la mesure où elle n’entravait pas la production de BIRS et de BCD 1.0 – et de l’éloignement physique d’ATG par rapport à Chicago, l’équipe d’ATG avait joui d’une grande liberté, qui s’est avérée être une liberté de travailler sur de nouvelles technologies. Un « chef de projet » pour BOL a en fait été nommé à Chicago, mais il s’est rarement rendu à La Jolla et a retardé l’adoption du courrier électronique jusqu’au début de 1994, date à laquelle il était trop tard pour découvrir qu’il n’avait qu’une vague idée de ce qui se passait sur la côte.
L’aspect peut-être le plus remarquable de la période ATG est que le groupe ne s’est pas retrouvé, en septembre 1994, sans rien à faire. Le lancement de BOL sur une base payante était, au contraire, l’ouverture qu’ils recherchaient. Parallèlement au développement de BOL, ils avaient travaillé sur des idées complémentaires, des idées d’améliorations et d’extensions qui, pensaient-ils, permettraient à BOL et peut-être à l’entreprise d’entrer dans le XXIe siècle. Ces idées étaient au nombre de trois : Bibliolinks, Mortimer et Gateway Britannica. Elles partageaient une prémisse essentielle : les attributs de la Britannica – ampleur et profondeur de l’érudition, exhaustivité, précision – pouvaient faire de BOL le centre de la partie sérieuse du World Wide Web.
Bibliolinks
L’idée de Bibliolinks est née d’une amélioration naturelle et apparemment simple. Si la Britannica était un résumé des connaissances humaines, chaque article était également un résumé des connaissances sur un sujet particulier. Tous les articles majeurs et plusieurs milliers d’articles plus courts fournissaient des références bibliographiques pour des lectures complémentaires, afin d’aider l’utilisateur qui souhaitait aller au-delà du résumé. La longueur des bibliographies varie d’un seul ouvrage à des enquêtes de plusieurs pages, très structurées, portant sur des domaines d’étude entiers. En outre, de nombreuses références à des ouvrages publiés figurent dans le texte même des articles.
Le projet a été réalisé par Belew et Steier, à partir de l’automne 1993. La première étape a consisté à développer un logiciel permettant de reconnaître les citations bibliographiques dans le texte ou les bibliographies des articles, de séparer les citations composant chaque bibliographie et de décomposer chaque citation en différents types d’informations permettant d’identifier un article particulier : titre, auteur, date de publication, etc. Cet effort s’appuie bien sûr sur la cohérence du style utilisé dans l’encyclopédie. Un autre programme a ensuite comparé ces citations aux enregistrements de Roger, le catalogue électronique de la bibliothèque de l’UCSD. Lorsque des correspondances pouvaient être établies avec un niveau de probabilité prédéterminé, le texte de la citation dans l’article était alors étiqueté comme un hyperlien pointant directement vers la « fiche » correspondante dans Roger.
Dans sa version bêta (qui n’a été officiellement diffusée sur le campus de l’UCSD qu’à l’automne 1995), Bibliolinks a été en mesure de trouver et de créer des liens vers Roger pour plus de 70 % des citations bibliographiques reconnues dans BOL, soit un total de plus de 200 000 liens, avec une précision d’environ 95 %.
Un utilisateur de BOL, lisant un article de Britannica et arrivant à une référence à un ouvrage publié ou à la bibliographie de l’article, pouvait voir d’un coup d’œil quels documents se trouvaient dans le système de bibliothèques de l’UCSD. En cliquant sur l’entrée, l’utilisateur accédait à la notice Roger, qui lui indiquait la cote du document physique, la bibliothèque qui le détenait et s’il était actuellement disponible ou en cours d’emprunt. À elle seule, cette fonction aurait fait de Bibliolinks un développement important. Cependant, comme les bibliothécaires l’ont rapidement reconnu, il existait une autre application, potentiellement encore plus précieuse : Bibliolinks pourrait servir de « front-end » ou d’outil de recherche en langage naturel pour la collection de la bibliothèque.
Alors que d’autres outils de recherche en ligne permettaient d’effectuer des recherches à partir du nom de l’auteur, du titre ou d’un ensemble relativement restreint de termes de recherche, Bibliolinks offrait la même capacité de recherche sophistiquée que BOL. En outre, pour les non-initiés, tels que les étudiants de premier cycle, et pour toute personne cherchant en dehors de son domaine d’expertise, l’outil BOL-Bibliolinks ne fournissait pas simplement une liste de fonds de bibliothèque pertinents, mais un guide de référence pour des lectures plus approfondies.
L’un des principaux avantages du projet Bibliolinks a été de forcer le groupe éditorial à entreprendre un projet de révision et de mise à jour des bibliographies qui n’avaient pas fait l’objet d’une attention suffisante et d’en ajouter d’autres à l’encyclopédie. Malheureusement, à l’exception de cet effort, le projet n’a pas abouti. Il a été reporté à plusieurs reprises et a souffert des fréquents changements de priorité qui ont entravé tous les projets d’extension.
Mortimer
Au début de l’année 1993, Clarke et Bartell ont commencé une série d’expériences sur la classification automatique des textes. Clarke a apporté à ce travail sa compréhension de la nature de la classification et son expérience de l’analyse automatisée des grappes, Bartell sa connaissance de l’application des réseaux neuronaux au problème de la recherche d’informations. On se souvient encore avec émotion des premières esquisses de Clarke d’une interface de recherche graphique, dans laquelle quelques cercles représentaient des thèmes généraux, à l’intérieur desquels étaient représentés des « hits » individuels (documents dans les données recherchées qui répondaient dans une large mesure aux critères des différents thèmes) ; les différents diamètres des cercles étaient proportionnels au nombre de hits tombant à l’intérieur de chacun d’eux, ou, comme on l’appelait à l’époque, à leur « grossesse ».
Pour construire son logiciel expérimental, Bartell a utilisé une technique mathématique appelée mise à l’échelle multidimensionnelle. En gros, des groupes de documents textuels ont été analysés statistiquement pour trouver des associations entre les éléments lexicaux (mots et phrases) qui les composent. Bien que certains termes puissent être caractéristiques de certains sujets, ils sont trop peu nombreux et trop peu fréquents pour servir d’indicateurs fiables pour chacun d’un grand ensemble de documents divers. En revanche, la tendance des groupes de termes à se retrouver ensemble selon certains schémas permet de mieux diagnostiquer le sujet, et c’est ce type de schémas que le programme de Bartell était censé détecter.
Entre-temps, Clarke a découvert la Propaedia. Ce volume de l’Encyclopædia Britannica consistait principalement en une « ébauche de connaissance » élaborée. Cette ébauche fournissait précisément ce dont on avait besoin pour construire un outil permettant non seulement de regrouper mais aussi de classer les documents, à savoir une taxonomie logique et approfondie des sujets. Dans le cadre de son étude de la Propaedia, Clarke est entré en contact direct avec le groupe éditorial de Chicago, qui lui a appris que chacun des quelque 64 000 articles de la partie Micropaedia de l’encyclopédie avait été classé en fonction du plan de la Propaedia. Une ou plusieurs balises indiquant la (les) classification(s) de chaque article faisaient partie du fichier texte de chaque article dans PSEdit.
Un ensemble d’entraînement d’environ 45 000 documents Micropaedia étiquetés (environ 70 % de l’ensemble) a été sélectionné et soumis à l’analyse. Le réseau neuronal a en effet « appris » à reconnaître les caractéristiques sémantiques des articles dans différentes catégories. Le premier test de l’efficacité du logiciel en tant que classificateur a consisté à soumettre les articles des 30 % restants, sans leurs étiquettes Propaedia, et à comparer la classification suggérée par le logiciel avec celle des éditeurs. La précision au niveau supérieur de la classification – les dix parties principales de la Propaedia – était d’environ 96% ; elle diminuait progressivement à des niveaux de plus en plus profonds, tombant à environ 75% au quatrième niveau. Lors des tests et démonstrations ultérieurs, la production du logiciel a généralement été maintenue à trois niveaux.
Le test suivant, beaucoup plus exigeant, consistait à soumettre au classificateur des documents textuels provenant d’autres sources. Au cours des nombreux mois de développement, des échantillons de données ont été obtenus du Los Angeles Times, du New York Times et de la nouvelle édition du Grove Dictionary of Music and Musicians, qui n’avait pas encore été publiée. Les résultats varient selon les sources mais sont uniformément bons, voire excellents. Les articles du Grove, rédigés dans un style similaire à celui de la Britannica, ont été classés avec une grande précision. Les articles du New York Times variaient en termes de style et de vocabulaire ; les articles d’actualité ont été très bien traités, tandis que certaines chroniques se sont avérées difficiles à placer dans l’espace thématique. L’inspection éditoriale de certains d’entre eux a montré qu’ils avaient tendance à être des réflexions sur ceci et cela, sans sujet cohérent ou fermement énoncé ; le classificateur, de manière intéressante, a eu tendance à les placer dans la catégorie Littérature.
Le système a été baptisé « Mortimer » par Kester, en l’honneur de l’initiateur de la Propaedia. L’élément essentiel de Mortimer était une méthode d’affichage des résultats des calculs effectués par le logiciel. En substance, pour chaque document analysé, un score de probabilité était calculé pour chaque thème possible, en l’occurrence 176 thèmes (le nombre de rubriques de troisième niveau dans la Propaedia). Ces scores constituent un vecteur dans un espace à 176 dimensions. Ce vecteur, ainsi que ceux de tous les autres documents analysés, devait ensuite être projeté sur l’espace bidimensionnel de l’écran de l’ordinateur. Une distorsion d’une sorte ou d’une autre était inévitable, et il n’y avait pas de réponse correcte unique ; en fait, un débat animé sur la manière de réaliser la visualisation a persisté pendant quelques mois. L’interface utilisateur adoptée pour les démonstrations au sein de Britannica et à l’extérieur, conçue par John Dimm, montrait les sujets sous la forme de grandes régions aux couleurs irrégulières. (La forme, la taille et la position relative de ces régions avaient déjà été calculées de manière similaire à partir des statistiques sémantiques de tous les documents d’apprentissage de chaque classification). En cliquant sur l’une de ces régions, celle-ci apparaissait au premier plan et révélait le niveau de classification immédiatement inférieur. De cette manière, l’utilisateur pouvait, en fait, naviguer vers le bas dans le schéma.
En mars 1995, Bartell et Clarke ont déposé une demande de brevet pour Mortimer ; leur brevet pour « Method and System for two-dimensional visualization of an information taxonomy and of text documents based on topical content of the documents » a été délivré en avril 1997.
Lorsque Mortimer recevait une requête de recherche, il déterminait quels documents de l’ensemble étaient pertinents, attribuait une valeur thématique à chacun d’entre eux et plaçait des points – indicateurs de « succès » – dans la carte thématique. Cette capacité était particulièrement impressionnante lorsque le terme de la requête était polysémique, c’est-à-dire qu’il pouvait avoir plusieurs significations différentes. Le terme préféré de Kester pour démontrer la puissance de Mortimer était « dépression », qui pouvait se référer à l’économie, à la psychologie, à la géologie ou à d’autres sujets. Voici le niveau supérieur de l’affichage par Mortimer des articles de Britannica correspondant au terme « dépression ». Les points verts indiquent les articles de Britannica. Le titre de l’article jugé le plus pertinent, parce que son titre correspond au terme de la requête, est également affiché. Si l’utilisateur décide que le sens de « dépression » qui l’intéresse se trouve dans le domaine de la vie humaine, il peut cliquer sur ce domaine pour obtenir une deuxième carte thématique au niveau suivant ; un autre clic ramènera la vue au troisième niveau. Notez que les titres des articles sont révélés dans le cadre de cette navigation vers le bas. Par ailleurs, si le domaine d’intérêt était la dépression géologique, l’utilisateur aurait pu cliquer vers le bas à partir de La Terre jusqu’à ce troisième niveau d’affichage.

Cette capacité à détecter et à distinguer les différents sens des termes de recherche est appelée « désambiguïsation ». Aucun moteur de recherche ordinaire ne pouvait faire cela ; aucun moteur de recherche ordinaire ne peut le faire aujourd’hui. Plus remarquable encore, Mortimer pouvait parcourir simultanément plusieurs bases de données distinctes de documents textuels. Les occurrences provenant de sources différentes apparaissaient comme des points de couleur différente sur la carte. (C’est cet aspect de l’outil qui est à l’origine de la troisième extension imaginée pour Britannica Online, la notion de Gateway Britannica.



Gateway Britannica
Cette dernière partie de l’histoire de la création de Britannica Online s’apparente davantage à un post-scriptum, dans la mesure où elle se penche sur une idée qui n’a jamais vu le jour, sans parler de la quitter. Il s’agissait d’une vision séduisante qui, de 1993 à 1995 ou peut-être 1996, a donné à l’équipe principale de BOL une direction et une grande partie de son élan.
Dès leur première rencontre avec l’Internet et surtout avec le World Wide Web, les éditeurs de la Britannica ont compris qu’ils se trouvaient au seuil d’un changement de paradigme (cette expression galvaudée est utilisée ici sans excuse ni ironie). (La Britannica imprimée et reliée avait toujours été imaginée dans le contexte de l’individu à la maison, où l’encyclopédie – quelle que soit son utilisation – dominait physiquement la bibliothèque, voire la pièce dans laquelle elle se trouvait. Les éditeurs devaient désormais imaginer l’encyclopédie, pour ainsi dire, rangée quelque part dans la bibliothèque du Congrès. La version électronique, qui n’existe pour l’utilisateur que sous la forme de tracés momentanés sur l’écran de l’ordinateur, pourrait bien n’être qu’une des innombrables bases de données disponibles dans un océan vaste et inexploré d’informations numériques. Le groupe ATG, dans une perspective tout à fait différente, et peut-être un peu plus tôt, a compris exactement la même chose. Le motif de Gateway était leur détermination commune à positionner Britannica, non pas comme une ressource parmi des myriades d’autres, mais comme un point d’entrée de choix pour tous les chercheurs sérieux de connaissances sur le Web. (L’une des présentations internes de Kester à la direction générale s’ouvrait sur une séquence animée dans laquelle des anges ouvraient une paire de portes ornées, au son d’un morceau de The Planets de Holst).
Mortimer était manifestement un élément clé de ce plan. Mortimer offrait la promesse d’un accès systématique, par thème et par requête, à un ensemble d’informations plus vaste que l’encyclopédie elle-même. L’encyclopédie aurait un double objectif : son contenu fournirait des informations de base sur des sujets intéressant les utilisateurs de Gateway, tandis que sa structure fournirait un moyen d’organiser et d’indexer le Web dans son ensemble (ou la partie du Web consacrée aux types de connaissances dont s’occupe l’encyclopédie). Les Bibliolinks rempliraient une fonction parallèle en ce qui concerne les bibliothèques physiques.
S’appuyant sur les démonstrations de Mortimer pour aborder le sujet, Kester et d’autres ont organisé des réunions exploratoires avec des représentants du New York Times, de la McGraw-Hill Encyclopedia of Science and Technology, du Grove Dictionary, entre autres, dans le but de comprendre comment des opérations aussi diverses pourraient coopérer dans le cadre d’un projet Gateway. L’intérêt était suffisamment grand pour que plusieurs éditeurs fournissent des données de test, comme indiqué ci-dessus. Kester a élaboré un plan d’affaires détaillé.
L’idée de Gateway n’a pas abouti. Cet échec est en partie dû aux difficultés financières de Britannica. Il était évidemment difficile de trouver de l’argent pour des projets ambitieux, mais les cadres supérieurs, estimant peut-être qu’ils ne pouvaient pas se permettre un seul faux pas, n’ont pas été en mesure de définir la moindre stratégie. Après la vente de l’entreprise au début de 1995, les nouveaux propriétaires ont été submergés par les problèmes immédiats. Lorsqu’une stratégie pour l’entreprise a enfin vu le jour, elle s’est avérée très différente de la vision de Gateway. Des membres clés ont commencé à quitter ATG, jusqu’au départ de Kester en 1999. Le bureau de La Jolla, réduit à la fin à l’élaboration des versions annuelles du CD Britannica, a fermé en 2001.

Le personnel de Britannica chargé des technologies avancées à La Jolla, Californie
Debout, de gauche à droite: Lisa Carlson (personnel de Merriam Webster), Lisa Braucher Bosco, Harold Kester, John McInerney,
Assis: Brian Bartel, Chris Cole, Rik Belew, Amy Steier, Robert McHenry (alors rédacteur en chef de l’Encyclopaedia Britannica), John Dimm, Bob Clark [c. 1995].



{kind=link}